
You’re likely to be familiar with the great Library of Alexandria. Established in the 3rd century BC, the library was the center of intellectual life in the Hellenistic world, drawing scholars from across the Mediterranean to collect and study its vast trove of manuscripts. Thought to hold a near-complete archive of all known human knowledge – from mathematics to philosophy – it became a symbol of the era’s pursuit of enlightenment. The legend goes that it was consumed by a catastrophic fire although in reality it’s likely that the library gradually faded, eroded by policy changes and conflicts. Either way, a vast repository of wisdom was lost.
With the advent of the internet, we have – for the time-being at least – something far grander in scale: a knowledge base almost too expansive to comprehend, and all quite literally at our fingertips. With the click of a button, and you can see every photograph of Howard as he explores Tutankhamun’s tomb; watch footage of Jesse Owens win gold at the Berlin Olympics or view any painting, sketch or poem from William Blake. And, of course, you can find a cat video for each and any occasion.
But post Generative-AI, things have noticeably started to change within the walls of this enormous digital archive. Take Google Image search – we were looking for some very particular reference material: depictions of frogs and toads in European medieval art (as one does). You might expect to stumble upon some niche, esoteric websites and blogs, carefully curated by enthusiastic specialists. Instead, some 50% or so of results came from OpenArt; Stable Diffusion; Midjourney… AI-generated slop produced to such a standard that, at a glance, they’re almost indistinguishable from a real reference.
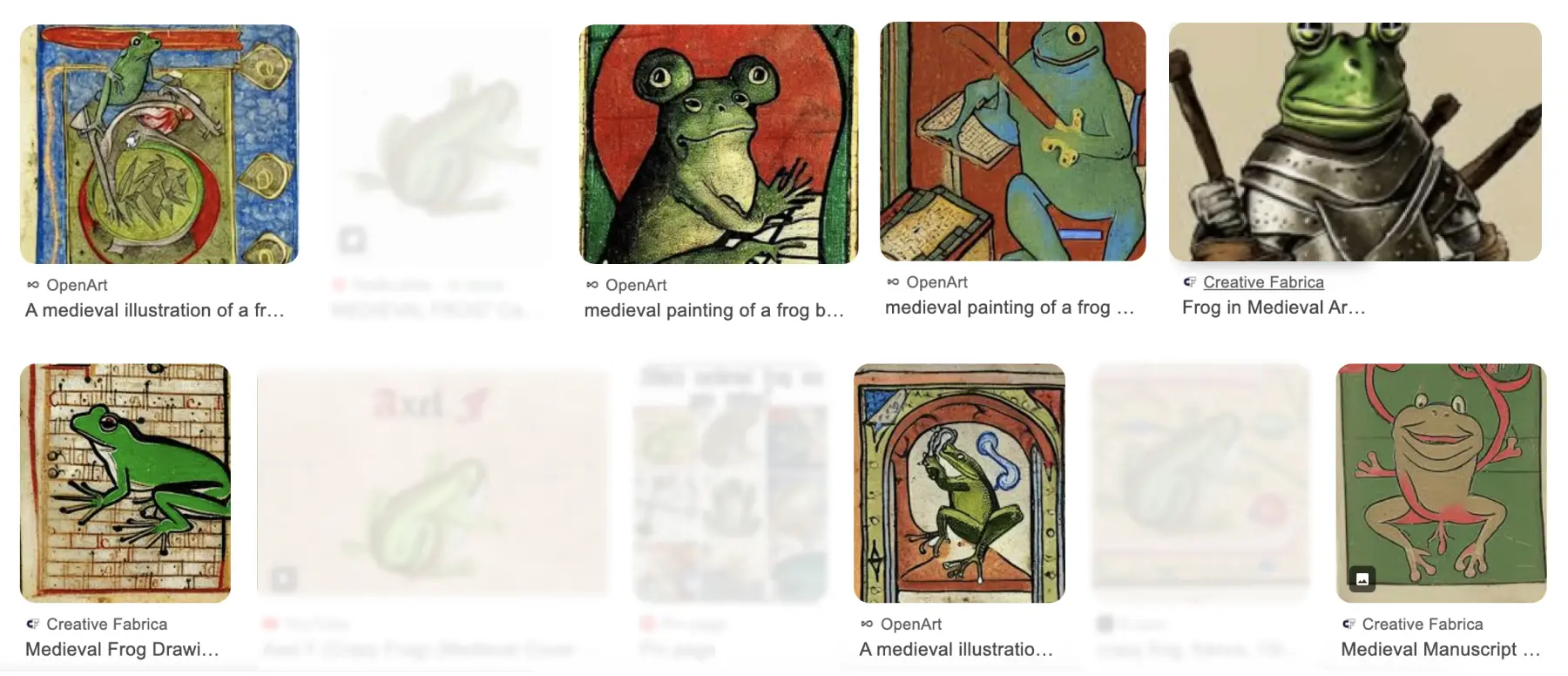
Try it yourself. Search for anything, and you’re likely to have similar findings: a sea of low-quality, inauthentic crap, drowning out anything of substance or value. One can reasonably assume that this is not what most users are looking for, so why is it happening? For starters, there’s the sheer volume: AI platforms generate vast quantities of images at an unprecedented speed, simply flooding the internet. Search engine algorithms prioritize fresh and abundant content, which inherently favors these easily generated images over more meaningful but less frequently uploaded material. Then there’s metadata: responding to a written prompt, Gen-AI images come pre-tagged with relevant keywords, alt text, and meta descriptions so they can easily be indexed and promoted by search engines. In short, they’re perfectly adapted to rank higher than many other sources, to the detriment of the rest of the digital ecosystem.
Alexandria 2.0 is not so much burning to the ground as it is being swamped before our eyes as search engines become increasingly dysfunctional and ineffective. It is to be hoped that some bright spark will create a browser extension to filter out synthetic results from those with substance. Maybe Ask Jeeves or Lycos could make a comeback with a brand new USP? In the meantime, we’ll be spotlighting resources we like over on our social channels. Here’s one for the road – the website for the Rijksmuseum in the Netherlands and their phenomenal digitized collection. Enjoy!

